Az előző bejegyzésekben sok általánosságról volt szó, ami azt gondolom, hogy segítheti a teljes kép megértését, viszont innentől kezdve egy fokkal konkrétabb leszek, a technológiai megoldásokba jóval részletesebben szándékozom belemenni.
Ha Big Data, akkor a Hadoop. De mi is ez a Hadoop?
A Hadoop az Apache Software Foundation egy projektjének keretében fejlesztett nyílt forráskódú keretrendszer, melynek célja nagy mennyiségű adat tárolása és feldolgozása elosztott rendszereken. A rendszer alkotóelemei általánosan elérhető hardverekből is állhatnak. A keretrendszer alapjait a Google által készített MapReduce és Google File System leírások szerint alkották meg.
![]()
Története
A projektet Doug Cutting, aki akkor a Yahoo!-nál dolgozott, és Mike Cafarella hozta létre 2005-ben, ami Cutting fiának játékelefántjáról lett elnevezve. Eredeti céljuk a Nutch kereső elosztásának támogatása volt. Ebben az elosztási technikában ütköztek problémába, amin a 2003-ban, a Google által kiadott, speciális fájlrendszerre vonatkozó architektúra leírás segítségével sikerül átlendülni. 2004-ben szintén a Google publikált egy dokumentumot a MapReduce eljárásról, amit 2005-re a Yahoo!-nál beépítettek a Nutch-ba. Kiderült, hogy a fájlrendszer és a MapReduce alkalmazható a keresési szolgáltatásokon kívül is, így 2006-ban a Nutch projekten kívül folytatta a pályafutását a korai Hadoop. (Lényegében egy új projektet hoztak létre számára E14 kódnéven.) 2008-ra az Apache kiemelt projektjévé vált, viszont ekkorra már más vállalatok is elkezdték azt intenzíven használni, köztük a Last.fm, Facebook, sőt a New York Times is! (via Wikipedia, Tom White - Hadoop: The Definitive Guide)
A közösség a kezdetek óta folyamatosan fejleszti az eszközt, az elmúlt utolsó negyedévében jött ki a 2.0-s változat, jelenleg a 2.3.0-s verziónál tartunk. (kiadás: 2014. február 20)
Természetesen azóta több vállalat is üzleti potenciált látott a Hadoop-ban, és megkezdődtek a saját disztribúciók fejlesztése, valamint tanácsadási, oktatási és üzemeltetési szolgáltatások nyújtására specializált vállalatok látták meg a napvilágot az elmúlt években. Élenjáró, legelterjedtebb disztribúciók jelenleg (elterjedtségük sorrendjében): Cloudera, MapR, Hortonworks. (via)
Apache™ Hadoop®
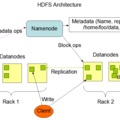
Ha elég magasról tekintünk a Hadoopra a következő sematikus ábrával illusztrálhatjuk a működési elvét:
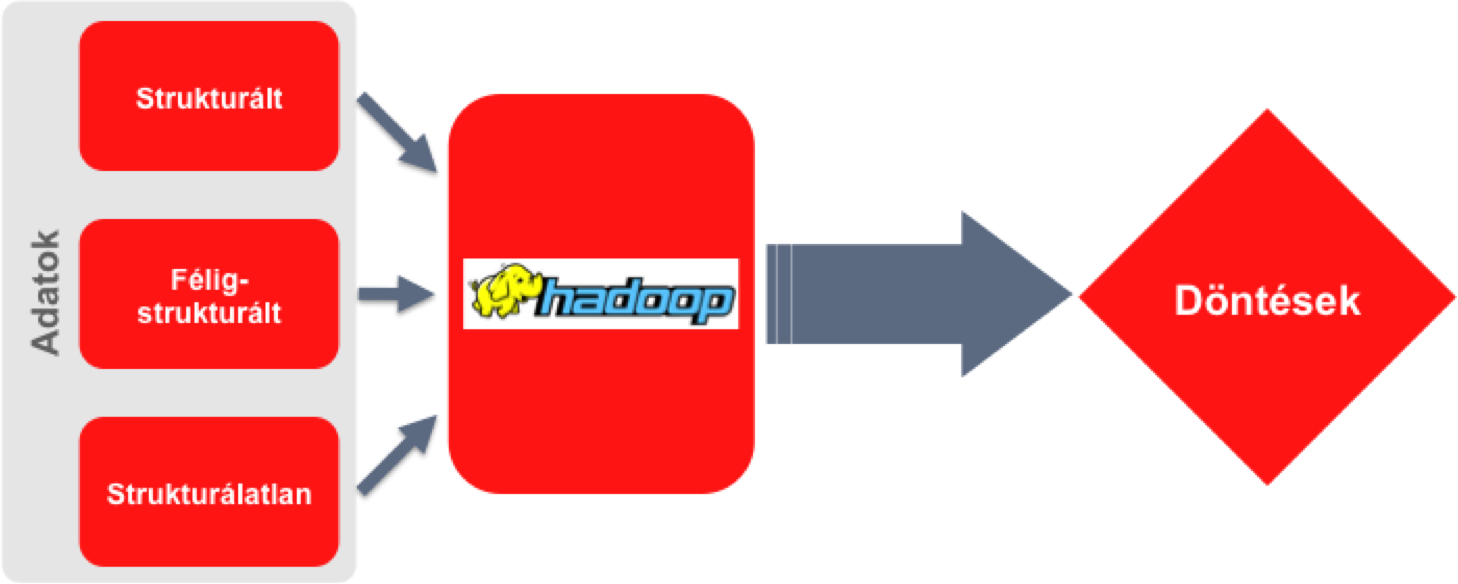
A Hadoop Core és annak kiegészítő alkalmazásai strukturált, félig-strukturált és strukturálatlan adatok elosztott rendszereken való tárolásával és feldolgozásával olyan információkat állítanak elő, melyek üzleti döntések fontos inputjai lesznek a vállalati információrendszerben.
Főbb tulajdonságai:
- Nyílt forráskódú, ebből fakadóan teljesen ingyenes.
- Beépített adatdisztribúció biztosít a klaszter tagjai között.
- Lehetőséget biztosít több helyszínen történő adatelemzésre, több helyszínen tárolt, de azonos adatforrásból.
- Nagyfokú skálázhatóság jellemzi.
- Megbízható hibakezelés a fejlett adatreplikációs eljárásoknak köszönhetően.
Különbségek a relációs adatbázisokhoz képest:
- Míg a relációs adatbázisok esetén az adattárolási séma meghatározására az adatok tárolásakor van szükség, a Hadoop, fájlrendszer jellegéből fakadóan, bármilyen típusú adat tárolására alkalmas előzetes séma definiálása nélkül is. A Hadoop a séma meghatározását akkor igényli, amikor a tárolt adat feldolgozására kerülne sor.
- Ebből következik, hogy míg az adatbázisokból az adatok olvasása, a Hadoopban az adatok írása gyors.
- A tárolt adatok strukturáltságában természetszerűen jelentős az eltérés. Adatbázisokba jól strukturált adatokat töltünk, Hadoop-ba bármilyen formátumú, strukturáltságú adat betölthető.
- A relációs adatbázisokat vertikális skálázhatóság jellemzi (scale-up), ez a Hadoop esetén viszont horizontális. (scale-out)